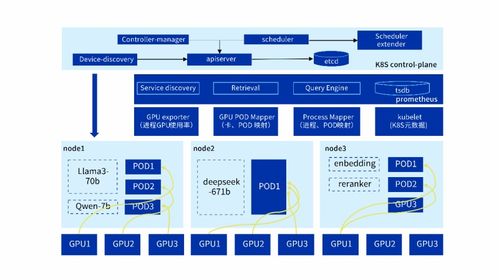
在人工智能技术迅猛发展的今天,AI业务已成为企业数字化转型和创新的核心驱动力。确保AI算力平台,特别是复杂异构GPU环境的稳定、高效与透明化运维,是支撑业务连续性与敏捷性的基石。为此,InCloud AIOS推出的可视化智能监控方案,为信息系统运行维护服务树立了新标杆,真正实现了让异构GPU资源“了如指掌”,保障AI业务7x24小时稳如磐石。
一、AI业务运维面临的核心挑战
随着大模型训练、深度学习推理等任务成为常态,企业AI算力基础设施往往由多种型号、不同架构的GPU卡混合构成。这种异构环境在带来灵活性与成本优势的也为运维带来了巨大挑战:
- 资源状态不透明:难以实时、统一地洞察所有GPU的利用率、显存占用、温度、功耗等关键指标。
- 故障定位困难:当训练任务失败或性能骤降时,快速定位是硬件故障、驱动问题、还是应用层瓶颈,过程繁琐耗时。
- 资源调度不精准:缺乏细粒度数据支撑,导致GPU资源分配不合理,部分卡过载而部分卡闲置,整体利用率低下。
- 运维效率低下:依赖命令行和分散的工具,缺乏全景可视化视图,无法实现预测性维护,被动响应问题影响业务连续性。
二、InCloud AIOS可视化监控方案的核心价值
InCloud AIOS方案深度融合了监控、管理与分析,旨在打造一个端到端、可视化的AI算力运维中枢。其核心价值在于:
- 全景可视,一览无余:通过统一的图形化仪表盘,动态展示整个GPU资源池的全貌。无论是NVIDIA、AMD还是国产化GPU,其实时状态(算力使用率、显存、温度、功耗、ECC错误等)均以图表、拓扑图等形式清晰呈现,彻底打破“黑盒”。
- 精准洞察,深度分析:不仅提供实时监控,更具备历史数据回溯与深度分析能力。可以对任意时间段、任意GPU或任务进行性能对比、瓶颈分析与趋势预测,为容量规划与性能优化提供数据驱动决策。
- 智能告警,主动运维:用户可基于丰富的指标自定义告警策略。系统能主动发现异常(如温度过高、显存泄露、XID错误等),并通过多种渠道即时通知,变“被动救火”为“主动预防”,极大提升MTTR(平均修复时间)。
- 关联拓扑,快速定界:将GPU监控与服务器、网络、存储及上层AI任务(如训练作业、推理服务)进行拓扑关联。当问题发生时,能快速展示影响范围,定位根因是在基础设施层还是应用层,极大缩短故障排查路径。
三、赋能信息系统运行维护服务
该方案极大地提升了传统信息系统运行维护服务在AI场景下的能力层级:
- 服务标准化:为异构GPU环境提供了标准化的监控指标体系和管理视图,使运维服务有据可依,交付物清晰可视。
- 操作自动化:集成常见的运维操作,如驱动版本概览、健康检查一键执行等,减少人工干预,降低操作风险。
- 报告智能化:自动生成资源利用率、性能表现、稳定性报告,为服务等级协议(SLA)评估和持续服务改进(CSI)提供客观依据。
- 成本可优化:清晰的资源使用画像帮助识别“僵尸任务”和低效资源分配,从而通过调度优化提升整体资源利用率,直接降低算力TCO(总拥有成本)。
四、
在AI算力即生产力的时代,算力基础设施的稳定与高效是业务成功的生命线。InCloud AIOS可视化监控方案,如同为异构GPU集群装上了“智慧之眼”和“数字神经”。它让运维人员从繁琐、被动的状态中解放出来,以全局、透明、智能的方式掌控算力资源,确保AI业务能够7x24小时不间断地稳健运行,为企业持续创新提供源源不断的澎湃动力。通过该方案,信息系统运行维护服务也得以进化,从基础保障角色转变为价值创造伙伴,共同护航企业的智能化征程。